




ProjetsOn 04/04/2023

Arca computing
Share
GRAPHQL, KÉZAKO ?

COMMUNIQUER, LA CLÉ DES APPLICATIONS MODERNES. LE WEB, ET SON PROTOCOLE NOUS PERMETTENT DES MERVEILLES DEPUIS TOUJOURS. AUJOURD’HUI, ON VOUS RACONTE LE DERNIER VENU DANS LA FAMILLE, GRAPHQL.
#1. UNE HISTOIRE DE DIALOGUE
Avant de parler de GraphQL, il est bon de comprendre dans quel contexte il est arrivé. Tous les produits tech ou presque reposent sur la discussion entre le client (un navigateur, une app mobile, …) et un serveur ou d’autres clients. Cette discussion est normée, c’est à dire que les deux parties s’accordent sur un contrat qui définit ce qui peut être dit et comment, c’est ce qu’on appelle une API (Application Programming Interface). Bien qu’applicable dans pleins de domaines, dans cet article nous nous intéresserons uniquement aux API web, donc « API web » sera simplement appelé « API“ pour le reste de la lecture.
Aux origines du monde, les API utilisaient le protocole SOAP (Simple Object Access Protocol), le trés mal nommé. En effet, des requêtes SOAP sont très complexes à écrire, encore plus à lire (pour un humain) car écrites en XML. Ne parlons même pas de maintenabilité.

Roy Fielding
Pour remédier à ces problèmes, un jeune doctorant du nom de Roy Fielding propose en 2000 sa thèse Architectural Styles and the Design of Network-based Software Architectures qui introduit un concept : REST (REpresentational State Transfer). Son but, écrire des API universellement reconnues, simples et lisibles. De nombreuses contraintes existent en REST, et on pourrait faire un article complet dessus, mais le plus simple à retenir est qu’une API REST sait communiquer avec les verbes d’actions HTTP : HEAD, OPTION, GET, PUT, POST, DELETE, et communique dans une grande majorité des cas en JSON. Révolution ! La méthode REST est la méthodologie la plus utilisée depuis sa définition, indétrônable depuis plus de 20 ans.
Cependant, REST a aussi ces limites. Bien souvent, chaque usage nécessite une route spécifique, et des problèmes de rétrocompatibilité obligent parfois les développeurs à créer des « endpoints » (points d’entrées d’une API composés d’une url et d’un verbe HTTP) spécifique pour chaque version.
Et c’est comme ça que GraphQL est né.
#2. ORIGINES
Développé par Facebook aux alentours de 2012, GraphQL est au départ un projet interne, mais a été open-sourcé en 2015 pour le plus grand plaisir des contributeurs. Comme souvent dans ce cas là, GraphQL a été utilisé par les amateurs et sur des petits projets perso, avant de gagner petit à petit en popularité jusqu’à ce que de grands groupes traduisent leur api en GraphQL, comme GitHub, Netflix, AirBnB, Audi, …

Proclamé par certain.e.s comme le replaçant des API RESTful, ce changement révolutionnaire tarde à se faire sentir malgré les grands noms l’ayant adopté. Cependant, à ARCA, on aime investiguer sur les pistes de l’avenir et GraphQL est clairement une option à considérer désormais, puisque l’on voit que ce terme est recherché dans plus d’une recherche sur deux sur Google.
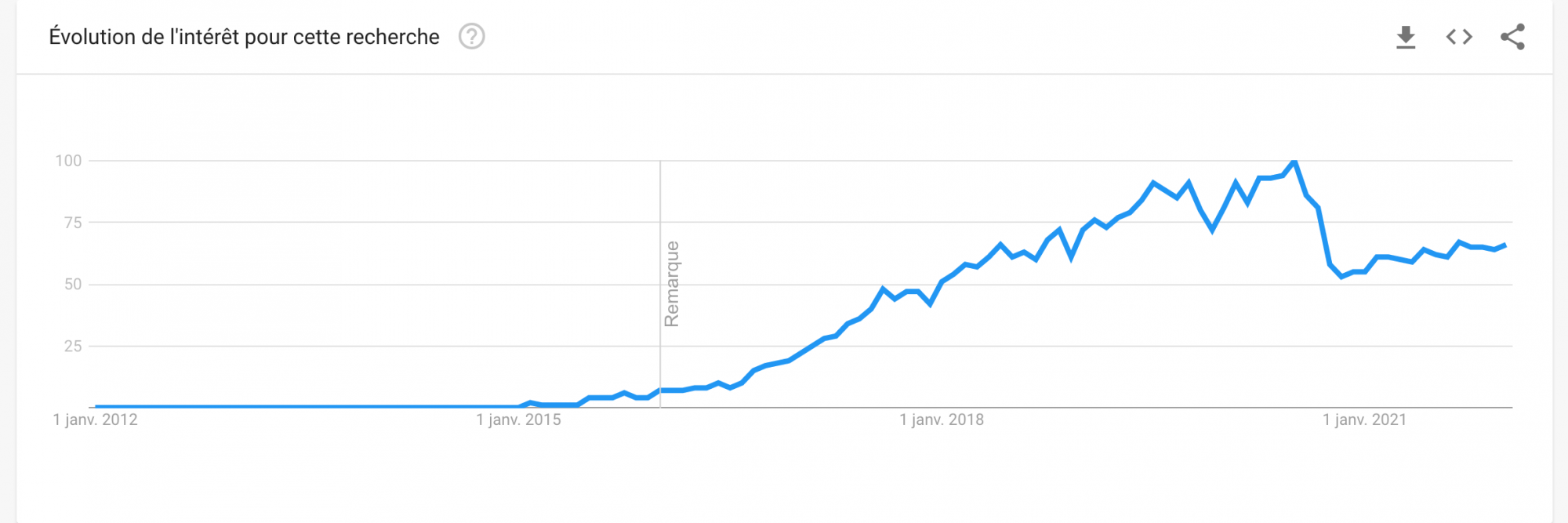
GraphQL Google Trend
#3. CONCRÈTEMENT, QU’EST CE QUE C’EST ?
Bon tout ça c’est très bien, mais on ne sait toujours pas à quoi ça ressemble tout ça ! Alors rentrons (un tout petit peu) dans le détail technique.
GraphQL est un langage de requête, qui se repose sur une grammaire nouvelle, on n’envoie plus des JSON comme dans une API REST mais des « query », qui existent au nombre de 3 : query, pour récupérer de la donnée (équivalente au GET), mutation pour en éditer (PUT, POST, DELETE, …), et subscription pour mettre à jour en temps réel (une websocket). Construire l’une de ces requêtes requiert d’expliciter tous les champs que nous souhaitons récupérer (nous en reparlerons). Par exemple :

Un contrat toujours à jour
Quand on construit une API en GraphQL, un schéma est généré. Il peut-être sauvegarder dans un fichier, ou récupérer directement via l’API (via une query évidemment !). Ce schéma est la source de vérité du serveur. C’est grâce à lui que nous savons quels champs sont valides dans nos requêtes, ce qu’il est possible de faire, de récupérer, si des champs sont deprecated ou non, etc. La query précédente est valide sur ce schéma :
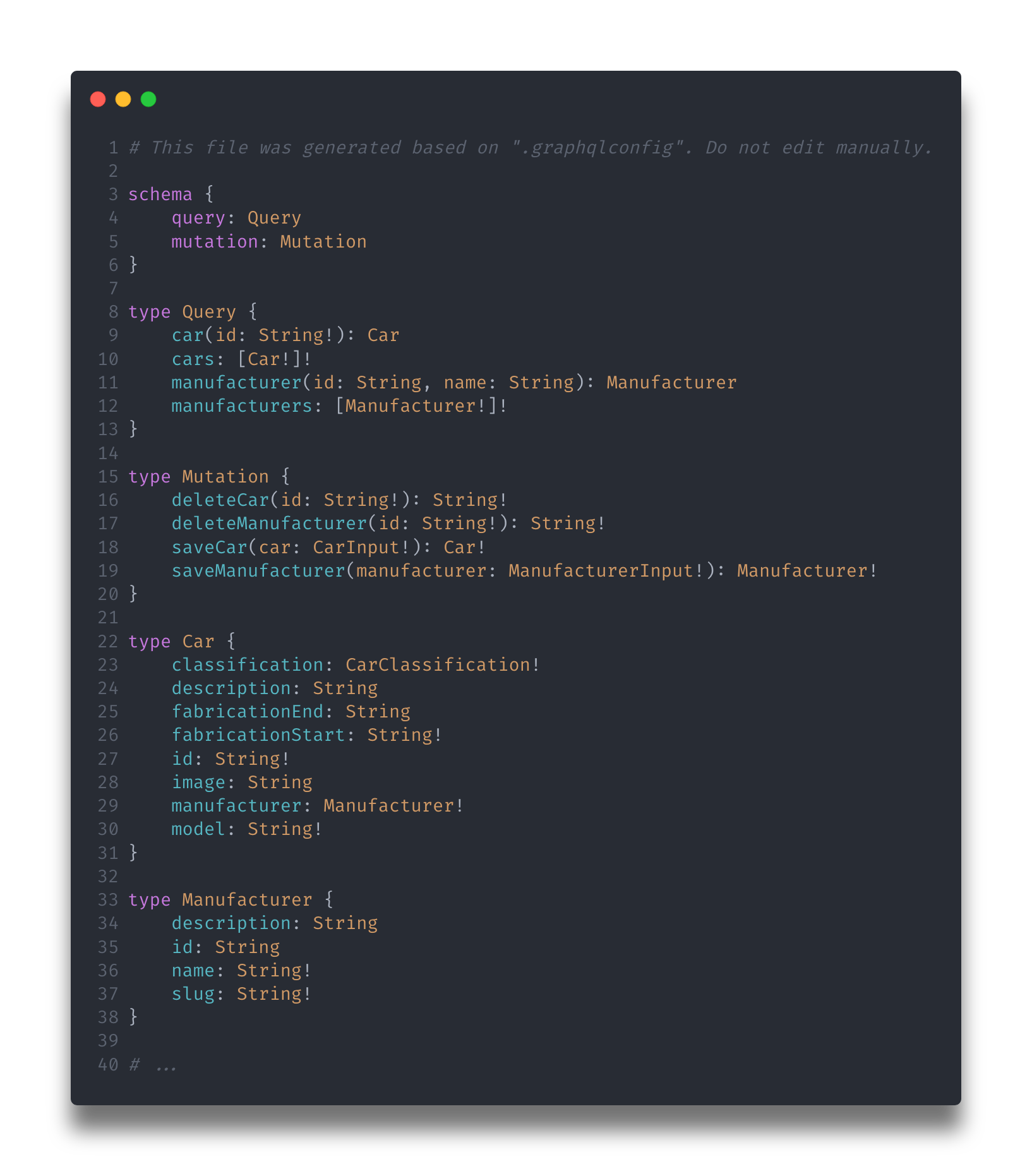
Adieu les versions grâce au schéma ! Le fait d’expliciter les champs dans chacune de nos requêtes permet d’assurer la rétrocompatibilité, et le schéma est toujours disponible aux clients de l’API. Ajouter un nouveau champ par exemple n’a aucun impact sur les requêtes existantes, et des directives comme @deprecated permettent de signaler une suppression de champs à venir.
Un typage presque inné
Autre avantage du schéma : vous ne trouvez pas qu’on dirait drôlement une définition de types ? Pratique pour forger nos objets métiers dans le langage de notre choix… Tellement pratique d’ailleurs, que des outils permettent la traduction automatique en fonction du schéma. Non seulement l’API est à jour, mais les types aussi.
Prédictibilité des résultats
Le schéma permet enfin une chose très importante : puisque l’on décrit ce qu’on souhaite recevoir, GraphQL assure la prédictibilité du format de retour. On obtient ce qu’on demande et c’est tout.
Fin de l’overfetching
Imaginons un produit à la fois mobile et web. Nous souhaitons afficher sur le mobile une liste des voitures avec leur nom et une image ainsi que la classification, mais sur l’application web nous souhaitons aussi y afficher le nom du constructeur et les dates de fabrication de la voiture, sans classification. En REST, deux options s’ouvrent à nous : créer une route /mobile/cars et une autre /web/cars, ce qui signifie 2 API à maintenir, ou alors une route unique /cars avec toutes les informations possibles, au risque de surcharger le réseau avec des données inutiles et laisser les applications jeter ce qui ne leur sert pas. Cela peut paraître anodin, mais sur des milliers de résultats suite à des centaines de requêtes, on commence à se rendre compte de la charge serveur… C’est ce qu’on appelle l’overfetching (récupérer trop de données faute de mieux, et laisser le client faire tout le travail qui aurait du être fait en amont par le serveur, ou appeler plusieurs ressources en cascade au fur et à mesure des informations que l’on obtient).
Heureusement, GraphQL répond à cela. Nous l’avons dit précédemment, une requête nécessite d’expliciter tous les champs que nous souhaitons récupérer et uniquement ceux là. Dans notre cas, cela signifie forger une query dans le schéma avec les champs désirés et l’application mobile n’aura simplement pas la même query que l’application web. Et évidemment, c’est aussi vraipour les champs à l’intérieur, là où en REST le constructeur (manufacturer dans le schéma) aurait souvent été ramené complet par simplicité.
Plus d’overfetching, ni de routes multiples à maintenir ! Elle est pas belle la vie ?
Évidemment ce ne sont que quelques exemples simples pour vous faire connaitre GraphQL, mais n’ayez crainte : nous venons à peine d’effleurer la surface de ce dont il est capable.
CET ARTICLE PREND QUELQUES RACCOURCIS, MAIS LE BUT ÉTAIT DE VOUS PRÉSENTER CETTE TECHNOLOGIE À LAQUELLE ON CROIT À ARCA. IL RESTE BIEN D’AUTRES CHOSES À DÉCOUVRIR SUR GRAPHQL. SI CETTE INTRODUCTION VOUS A SÉDUIT, IL NE TIENT QU’À VOUS D’APPROFONDIR LE SUJET GRÂCE AUX NOMBREUSES RESSOURCES DÉJÀ DISPONIBLES !
- Views162
0 comments
C
The articles of Arca computing
PortraitsOn 20/02/2023
PortraitsOn 15/08/2022
PortraitsOn 30/06/2022
On 07/06/2022
On 07/06/2022